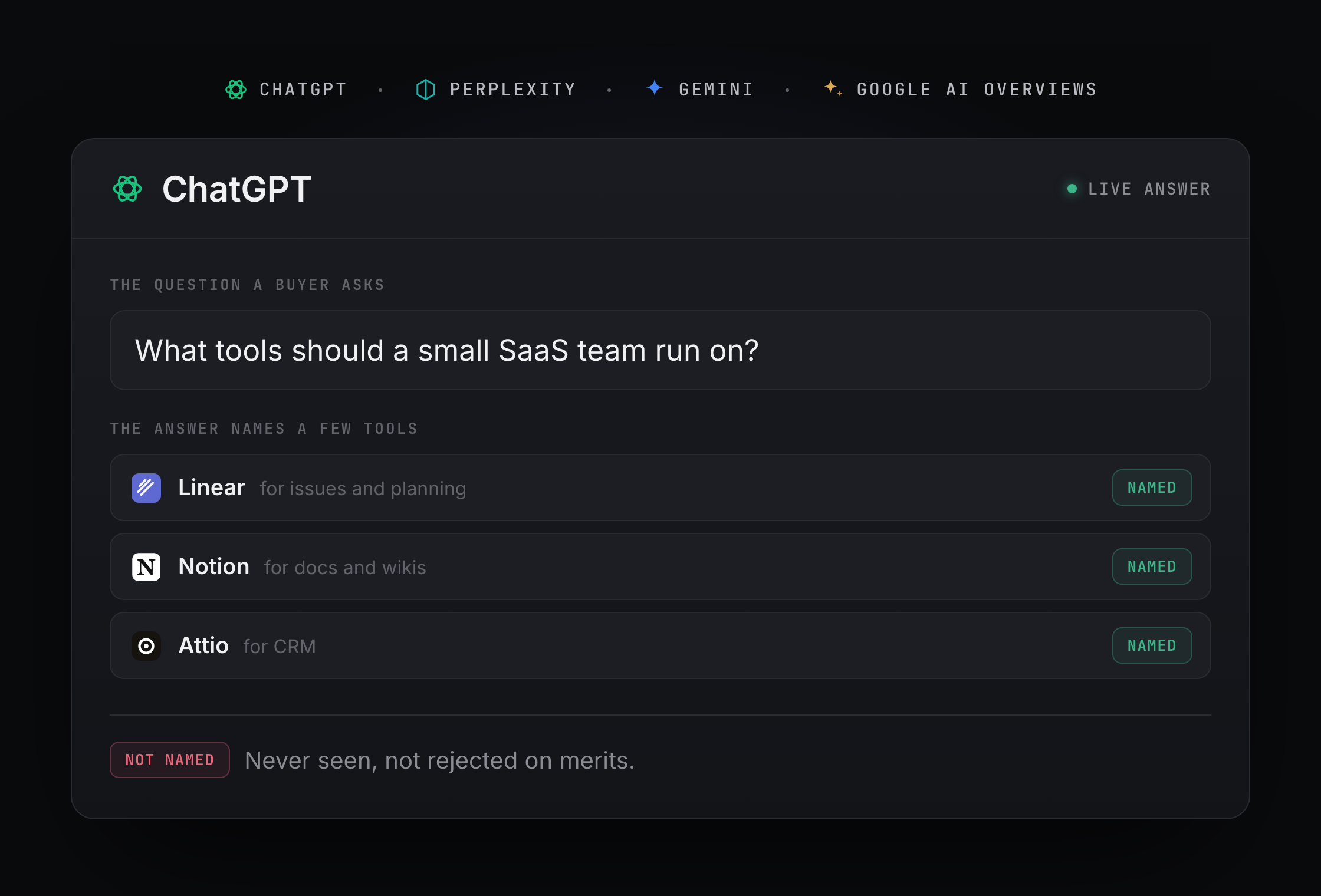
Open a fresh ChatGPT window and ask it for the best tool in your category. Watch what comes back. If you are like most post-launch founders, you will read a tidy list of three to five names, presented with confidence, and yours will not be on it. The products that are on it are not always better than yours. They are more legible to the model.
This stings in a particular way. You can ship a genuinely good product and still be absent from the exact moment a user is deciding what to try. The assistant did not weigh you and reject you. It never saw you. That is a different problem from being beaten on merits, and it has a different fix.
This post is about that fix. Not the abstract version, the mechanical one. Why a language model names some products and not others, what those named products have that you do not yet, and the order in which to close the gap.
- AI assistants name products they can read clearly from independent sources, not the ones that try hardest to be named.
- Competitors win because their product is legible: a plain description, consistent mentions, and presence where the model already looks.
- Absence is usually a structure problem, not a quality problem. Fix what the model can see before reworking the product itself.
- AI visibility compounds. Each consistent mention makes the next one easier, and the gap with rivals widens quietly over time.
How an AI assistant actually decides who to name
It helps to drop the idea that the model is ranking products the way a search engine ranks pages. It is not running your category through a scoring function. It is doing something closer to recalling and assembling. When you ask for the best project management tool for small teams, the model is reconstructing an answer from patterns it has seen many times across many sources, and from whatever it can retrieve at answer time.
Two things drive whether your product surfaces in that process. The first is whether you exist in the material at all. The second is whether, when you do exist, the surrounding context makes you easy to lift cleanly into an answer. Most absent products fail the first test. Most present-but-ignored products fail the second.
Presence: are you in the material at all
A model trained on a snapshot of the web knows what the web said about your category as of that snapshot. If your product launched after that, or launched quietly, or was only ever discussed on your own domain, the base model has little to recall. Retrieval-augmented systems like Perplexity, Google AI Overviews, and the browsing modes of ChatGPT and Gemini soften this by fetching live pages, but they fetch from the same surfaces that already rank and already get cited. Absence compounds. If nobody writes about you, there is nothing to retrieve, so the assistant keeps recommending the products people do write about, which gives those products more presence, and the loop tightens.
Presence is not one channel. It is the sum of every place a model might encounter your name in context: a Reddit thread comparing options, a Hacker News comment, a directory listing, a review on G2, a comparison article, a blog post that mentions you in passing, your own documentation. Your competitors who win AI answers are usually not winning one of these. They are present across most of them.
Citability: can you be lifted cleanly into an answer
Presence gets you considered. Citability gets you named. A model assembling an answer prefers sources it can quote or paraphrase without ambiguity. A page that states plainly what a product is, who it is for, and what it does is easy to lift. A page wrapped in vague positioning, where the actual function is buried under adjectives, is hard to lift even when the product is excellent.
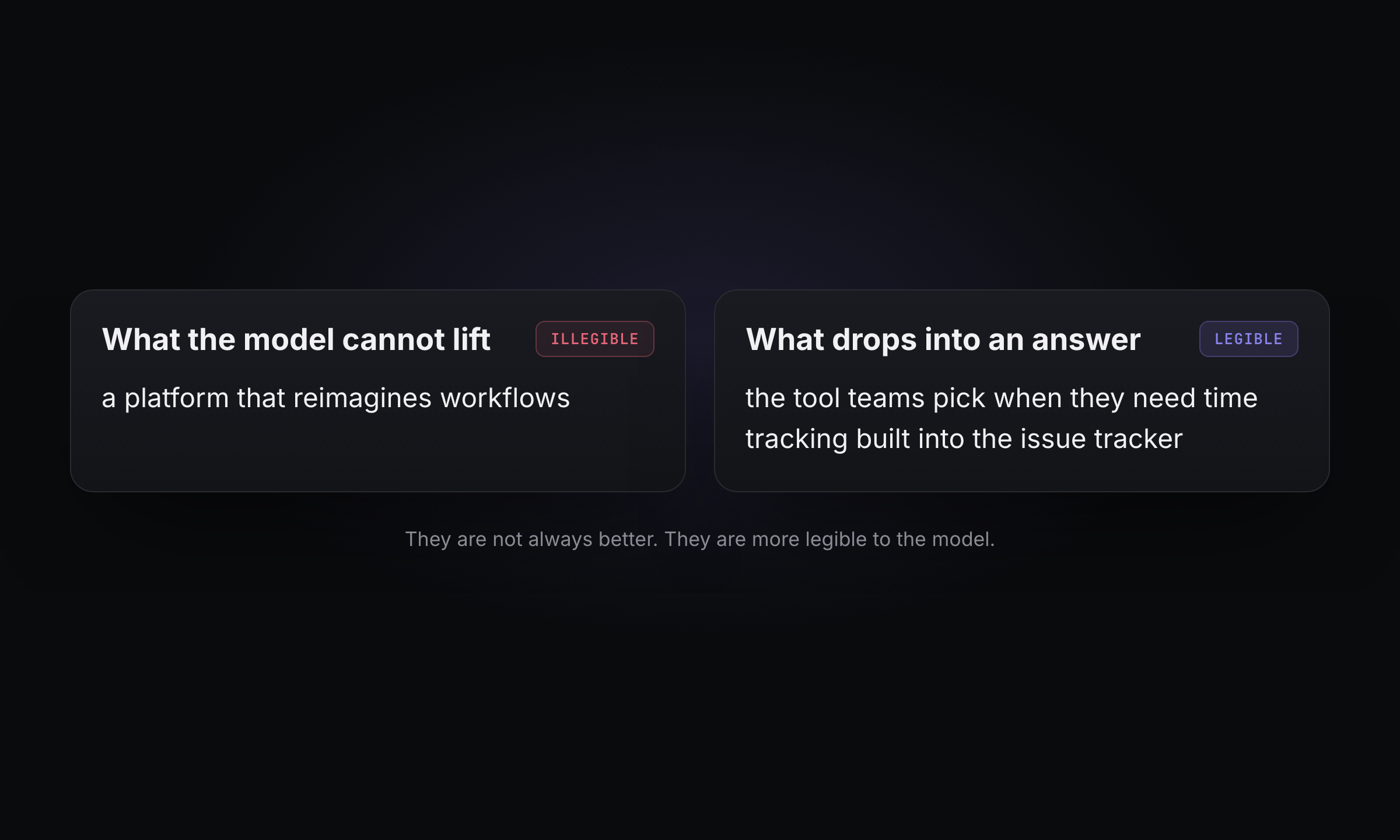
Think about what the model needs to produce a clean recommendation. It needs a name, a category, a concrete use case, and ideally a distinguishing fact. If your homepage says you are a platform that reimagines workflows, you have handed the model nothing it can use. If a comparison article says your tool is the one teams pick when they need time tracking built into the issue tracker, the model can drop that straight into an answer. Citability is mostly about being legible, and legibility is something you can write your way into.
What the products that win AI answers actually have
Pull apart any product that consistently shows up when you ask an assistant for the best option in a category, and you tend to find the same three properties. None of them require being the best product. All of them are achievable for a small team that decides to work at it.
Third-party validation, not self-description
Models weight what others say about you more heavily than what you say about yourself, for the same reason a sensible person does. Your own site asserts you are great. A Reddit thread where three strangers independently mention you because they actually use you is a different kind of evidence, and the model treats it that way. The products that win answers have accumulated a body of third-party mentions: forum threads, community recommendations, listicles, reviews, comparison pages written by people who are not them.
This is why a product can dominate AI answers without spending on ads. Somewhere along the way, real people started talking about it on surfaces the models read, and that conversation became the raw material every assistant now reassembles. You do not need that conversation to be huge. You need it to exist, to be specific, and to live somewhere a model can reach.
A consistent, concrete category frame
Winning products tend to be described the same way everywhere. Their homepage, their directory listings, the threads about them, and the comparison articles all converge on roughly the same sentence about what the product is and who it is for. That consistency is not an accident of luck. It is what happens when a product states its frame clearly enough that other people repeat it back.
When your framing is consistent, every mention reinforces the same association in the model's view of the category. When it is scattered, where you call yourself a platform here, a tool there, an operating system somewhere else, each mention pulls in a different direction and none of them accumulate. The model cannot form a stable picture of what you are, so it reaches for products it can describe in one clean line.
Content shaped like an answer
The products that get cited often publish content built to answer the exact questions users ask. Not keyword pages stuffed for an old ranking algorithm, but pages that state a question and answer it directly in the first lines, then support the answer. A page titled best tools for X that opens by naming the options and saying which fits which situation is content a model can quote almost verbatim. A page that buries the answer under five hundred words of preamble is not.
There is a deeper point here than chasing your own keywords. Comparison and alternatives pages, the ones users actually consult before deciding, are frequently written by third parties about your competitors and not about you. If the only best-X-tools article in your category lists five products and you are not one, that article becomes a source the assistant leans on, and your absence from it becomes your absence from the answer.
For the broader version of this argument, the shift from ranking pages to being cited in answers, see The new playbook for organic growth in the AI search era. →The specific reasons you are absent
It is worth being concrete about which of these is your actual problem, because the fixes are different and the order matters. Most post-launch founders are absent for one of a small number of reasons.
- You are too new. You launched after the model's training snapshot and have not yet built enough live presence for retrieval to find you. This is the most common case and the most fixable.
- You only talk about yourself on your own domain. Everything written about you was written by you. There is no third-party material for a model to weigh.
- Your framing is incoherent. You are mentioned in places, but described differently everywhere, so no stable association forms.
- You are missing from the surfaces models read. You have a great site but no presence in the communities, directories, and comparison content where decisions get reconstructed.
- Your content answers nothing. You publish, but the pages are positioning, not answers, so nothing is quotable.
Notice that none of these is about product quality. You can fail every one of them while shipping the best tool in the category. That is the frustrating part and also the hopeful part, because every item on that list is something you can change without rebuilding the product.
How to close the gap, in order
The work breaks into a sequence. Doing it in order matters, because validation built on incoherent framing just spreads the incoherence faster.
First, fix the frame
Write one sentence that says what your product is, who it is for, and the concrete thing it does. Not the aspirational version. The version a stranger could repeat after reading it once. Put that sentence on your homepage, in your directory listings, in your documentation, and anywhere else you describe yourself. You are giving the model, and the humans who will write about you, a clean line to copy. Until this is consistent, every other action multiplies confusion rather than reach.
Then, build presence on the surfaces that count
Get listed where products in your category get listed: the relevant directories, the review sites, Product Hunt if it fits, the obvious places a user might browse. Show up authentically in the communities where your users already discuss the problem, Reddit and Hacker News and the niche forums, not by dropping your link but by being useful in threads where your product is genuinely the answer. Earn the third-party mentions that you cannot write yourself. This is slow and it is the part most founders skip, which is precisely why it is where the gap lives.
If you want the diagnostic angle on this, why a model omits you and how to read its answers as a signal, read Why you are invisible in ChatGPT. →Then, publish content shaped like answers
Write the comparison and alternatives pages that do not yet exist for your category, or that exist but omit you. Answer the real questions users ask before they decide, and answer them in the first lines. If you are present, framed consistently, and publishing material a model can lift cleanly, you have built every condition a product needs to start appearing in answers. The assistant does the rest, because you have finally given it something to work with.
The compounding part nobody mentions
Here is what makes this worth the patience. Presence compounds in the same loop that currently works against you, only in your favour. Once a few real mentions exist, you start showing up in answers. Showing up in answers sends users who then talk about you, which creates more mentions, which makes you show up more. The same flywheel that has been quietly recommending your competitors begins, slowly, to include you. It is slow to start and hard to stop once it turns.
The hard part is that this work is spread across surfaces you do not control and cannot see all at once. You cannot watch every Reddit thread, every directory, every assistant's answer to know whether you are gaining ground. This is the gap AfterLaunch is built to close. It monitors where your category is discussed and decided, scores your discoverability across the dimensions that matter, drafts the work in your voice for you to approve, and proves what changed through your analytics and rank tracking. You stay the one deciding what ships. It handles the part that is too distributed to track by hand.
If you want to know which of the reasons above is actually yours, the free Growth Snapshot scores your discoverability across seven dimensions and shows you where the gap sits. Start there. The model is already answering the question your users are asking. The only question left is whether your name is in the answer.
Why does a worse product than mine keep getting named in AI answers?
AI assistants are not ranking products by quality. They are assembling an answer from sources they can read and trust, so a product that describes itself plainly and gets mentioned consistently elsewhere is easier to name than a better product that is hard to parse. Legibility beats quality at the recommendation stage. The fix is making your product as readable to a model as your rival's, not making it better than it already is.
Can I just ask the AI assistant to recommend me?
No, and trying to game the model directly tends to backfire. Assistants draw on what independent sources say about you across the web, so the lever is the surrounding evidence rather than the prompt. You influence the answer by being described consistently in places the model already reads, not by addressing the model itself.
How do I find out which AI answers are leaving me out?
Run the questions your customers would actually ask across the major assistants and record who gets named. The free Growth Snapshot does a version of this across AI search and several other discoverability dimensions, so you can see the specific prompts where rivals appear and you do not. Start from real questions, not your brand name, because that is how customers search.
How long does it take to start showing up after I fix the gaps?
It varies by how often the assistants refresh their view of your category, and we will not pretend there is a fixed number. What we can say honestly is that the structural fixes (a clear description, consistent naming, presence where the model looks) are prerequisites, and nothing improves until they are in place. Treat it as steady groundwork rather than a switch you flip.