Ask four AI assistants the same question and you get four different answers. Ask ChatGPT for the best onboarding tool for B2B SaaS, then ask Claude, then Gemini, then Perplexity. The lists rarely match. Sometimes they barely overlap. This is not a bug. It is the direct consequence of how each engine builds an answer, and once you understand the mechanism, the work becomes obvious.
There is no single AI search you optimise for. There are several systems with different appetites. A founder who wants to show up has to understand what each one eats. This post walks through ChatGPT, Claude, Gemini and Perplexity one at a time: where each draws its facts from, why they disagree, and what concretely makes your product citable in each.
- No single tactic wins all four engines at once. Each one sources answers differently, so visibility is a portfolio, not a switch.
- Perplexity rewards fresh, citable pages it can fetch live. ChatGPT and Claude lean harder on what they absorbed during training, so third-party agreement matters more.
- Gemini and Google AI Overviews ride on top of classic search, so the SEO fundamentals you already know still carry weight here.
- Start with the pages and third-party mentions that all four engines can read, then tune for the engine where you are weakest.
The two ways an engine finds your product
Before the per-engine detail, hold one distinction in your head, because it explains almost everything that follows. An AI assistant can know about your product in two ways, and they are not the same.
From the training corpus
The model was trained on a large snapshot of the web and other text, frozen at some point in the past. If your product was discussed widely enough, by enough independent sources, before that cut-off, the model carries a fuzzy impression of it in its weights. This is why an older, well-covered tool gets named even when the assistant is not browsing. It is also why a product launched last month is invisible to the raw model: it simply was not in the training data.
Training memory is durable but slow and lossy. You cannot edit it. You earn your way into it over months and years of being mentioned across the open web, and the model remembers categories and reputations more reliably than it remembers exact feature lists.
From live retrieval
The other path is retrieval. The assistant runs a search at the moment you ask, reads a handful of pages, and writes its answer from what it just found. This is fast, current, and the only way a new product can appear at all. It is also fragile: the answer is only as good as the pages the engine happened to pull, and those pages change daily.
Most of the assistants now blend both. They lean on training memory for the shape of the answer and reach for retrieval to fill in specifics or check currency. The blend ratio differs by engine, and that ratio is the single biggest reason the four answers diverge. If you only remember one thing: the engines that retrieve heavily are the ones a pre-traction founder can influence this quarter. Training memory is the long game.
How to show up in ChatGPT
ChatGPT is the engine most people picture when they say AI search, and it is the hardest to reason about cleanly because it behaves differently depending on the mode and the question. Some answers come straight from the model's training memory with no browsing at all. Others trigger a live web search and arrive with citations. You do not always control which.
For a recommendation question, the behaviour tends to follow the cut-off. Ask for established tools in a mature category and ChatGPT often answers from memory, naming the incumbents it absorbed during training. Ask about something recent, niche, or explicitly current ("as of this year"), and it is more likely to browse. When it browses, it reads ranking-style pages: listicles, comparison articles, category roundups, and the kind of well-structured documentation that answers a question directly.
What makes you citable here
Two things, on two timelines. The slow one is presence across the open web: being named in third-party roundups, comparison posts, community threads and directory listings so that the next training snapshot carries an impression of you. You cannot rush this, but you can start it now, because today's published mentions are tomorrow's training data.
The faster one is being the page that browsing mode wants to read. That means content that states plainly what your product is, who it is for, and how it compares, in clean prose a model can lift a sentence from. A page titled for the exact question ("best X for Y") that answers in the first paragraph beats a clever brand-led page that buries the answer. ChatGPT, when it browses, is doing triage at speed. Be skimmable.
How to rank in Perplexity
Perplexity is the friendliest engine for a founder without a reputation, because it is retrieval-first by design. Nearly every answer is built from a live search, and every claim carries a numbered citation back to a source. There is far less reliance on frozen training memory. If your page is in the set Perplexity retrieves for a query, you can be cited today, with no waiting for a future model.
This makes Perplexity the closest thing to classic search in the AI era, and it rewards classic discipline. It runs a real retrieval step, so the pages that rank well in conventional search and answer the question directly tend to be the ones it pulls. The citation model also means you can verify your work: ask Perplexity the questions your customers ask, read which sources it cites, and you have a precise list of who is currently winning the answer and what kind of page does it.
What makes you citable here
Be retrievable and be quotable. Retrievable means your relevant pages are indexed and rank for the real question, the same fundamentals as search: a page that matches intent, clear structure, enough authority signals to be trusted. Quotable means the answer to the question lives in clean, self-contained sentences near the top, not scattered across a long narrative. Perplexity lifts a line and attributes it. Give it a line worth lifting, phrased so it stands alone without the surrounding paragraph.
Because Perplexity surfaces its sources so openly, it is the best free instrument you have for diagnosing your AI visibility across all four engines. The pages it cites are a strong proxy for what the others reach for when they browse.
How to show up in Gemini and Google AI Overviews
Gemini is interesting because it sits inside Google's gravity. The standalone Gemini assistant and the AI Overviews that now appear above many Google results both draw on Google's live index and its understanding of the open web. If you have done the work to be findable in Google, you have already done much of the work to be eligible here, because the retrieval substrate is largely the same machinery you have spent years trying to rank in.
That is the opportunity and the trap. The opportunity: ordinary search visibility carries over, so a founder who ranks for a real question has a path into the generated answer above it. The trap: AI Overviews increasingly resolve the question on the results page itself, so being eligible for the answer matters more than ever, because the blue link below it gets fewer clicks than it used to. Being the source the overview is built from is worth more than ranking fourth underneath it.
What makes you citable here
Treat it as an extension of good search practice with one added demand: structure for extraction. Google's systems favour content where the answer to a specific question is cleanly identifiable. A clear heading that poses the question, a direct answer beneath it, sensible use of structured data where it fits, and pages organised around real queries rather than brand themes. The same content that earns a featured snippet is the content most likely to feed an overview. You are writing for a system that wants to pull a self-contained answer out of your page and present it on your behalf.
- Lead each page with the question it answers, phrased the way a person would type it.
- Answer in the first paragraph, then expand. Do not bury the conclusion.
- Use headings that map to distinct sub-questions, so the engine can extract one cleanly.
- Keep the factual claims plain and checkable. Models distrust vague marketing language.
How to get cited by Claude
Claude leans more on its training and reasoning than on aggressive live browsing, though it retrieves when a question needs current information or when the user enables it. For recommendation questions, this means Claude often answers from what it absorbed during training: it tends to name products it saw discussed thoughtfully and repeatedly across credible sources, and it is comfortable saying it is not certain rather than inventing a confident list.
Practically, Claude rewards depth of reputation over freshness of page. A product that has been written about carefully, compared honestly, and discussed in places where people reason out loud, communities, considered blog posts, technical write-ups, builds the kind of impression Claude carries. Thin, keyword-stuffed pages do less for you here than one genuinely useful comparison that a real person found worth linking.
What makes you citable here
Play the reputation long game, and make the reputation legible. Earn substantive, independent mentions: a thread where someone explains why they chose you over an alternative, a write-up that compares you fairly, documentation that demonstrates you do what you claim. The signal you want the model to absorb is not "this product exists" but "this product is the sensible answer to this specific need." That is built over time, through being genuinely useful and being discussed, not through volume.
If your category is new or you launched recently, accept that training memory will lag. The interim play is to be strong on the retrieval-first engines while the durable reputation accrues, so you are visible now and remembered later.
If your product is currently absent from these answers, start with the diagnosis: why you are invisible in ChatGPT. →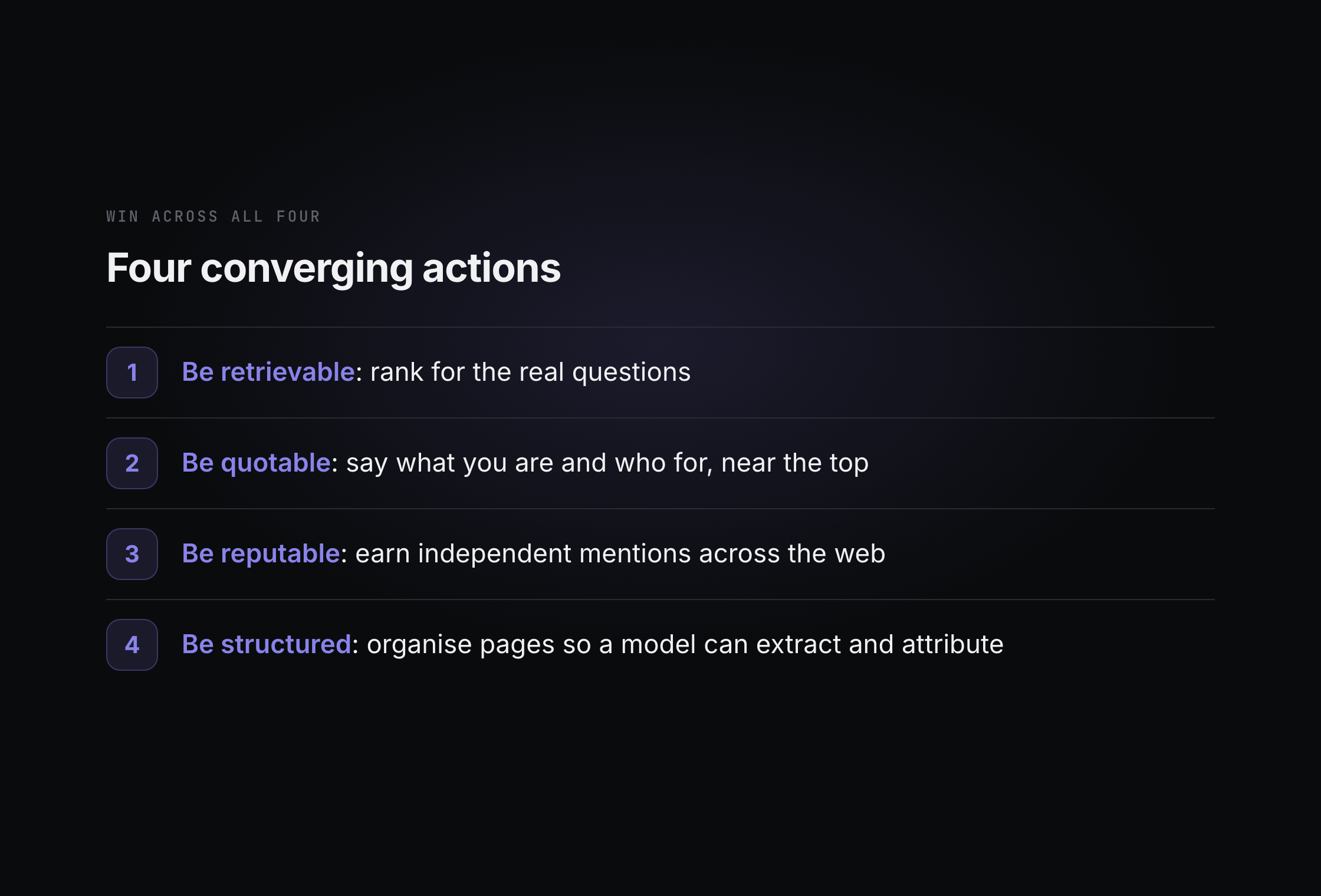
Why the four answers fragment, and what to do about it
Now the divergence makes sense. Perplexity answers mostly from a live search, so it reflects whatever is rank-worthy and quotable today. Claude answers mostly from training, so it reflects accumulated reputation. ChatGPT and Gemini sit between, switching between memory and retrieval depending on the question. Same query, four different sourcing mixes, four different answers. You are not trying to game one algorithm. You are trying to be the obvious answer across systems that decide in different ways.
The reassuring part is that the underlying work converges. Almost everything above reduces to the same handful of actions, weighted differently per engine.
- Be retrievable: rank for the real questions, because every engine that browses pulls from search-like results.
- Be quotable: state what you are, who you are for, and how you compare in clean, self-contained sentences near the top of the page.
- Be reputable: earn independent, substantive mentions across the open web, because that is what becomes durable training memory.
- Be structured: organise pages around real questions so a model can extract a clean answer and attribute it to you.
Do those four well and you are not optimising for ChatGPT or for Perplexity. You are becoming the kind of source any reasonable system reaches for. The per-engine differences then decide how quickly each one catches up to that, not whether it ever does.
Where to start this week
Run the test from the first paragraph yourself. Take the three or four questions your best customers would actually ask before choosing a tool like yours. Put each one to ChatGPT, Claude, Gemini and Perplexity. Write down who gets named, and on Perplexity, click through to the cited sources. Within an hour you will have a concrete map: which engines mention you, which mention competitors, and exactly which pages are winning the answer you want.
That map is the brief. The competitors who appear are the ones whose retrievable, quotable, reputable footprint is ahead of yours. The cited pages tell you the format that wins. From there the work is unglamorous and compounding: publish the pages that answer the real questions plainly, earn the independent mentions that build reputation, and keep checking the answers as they shift.
Keeping that check current across four engines, every week, is the tedious part, and it is the part most founders quietly drop. AfterLaunch watches those surfaces, tracks where you are cited and where a competitor took the answer, and drafts the pages and mentions to close the gap in your own voice for you to approve. The free Growth Snapshot scores your discoverability across seven dimensions and shows you the map before you write a word.
Related: why competitors keep winning the AI answer, and how to take the citation back. →Do I need a different content strategy for each of the four engines?
Not entirely. The foundation is shared: accurate, self-contained pages about what your product does, plus agreement across independent third-party sources. On top of that foundation you tune for the engine where you are weakest. Perplexity rewards freshness and fetchable pages, while ChatGPT and Claude lean more on what they absorbed during training and on cross-source agreement.
Why does my product show up in one engine but not the others?
Because the engines source answers through different mixes of live retrieval and training-data recall. A page that Perplexity can fetch and cite on demand may not yet exist in another engine's training corpus, so that engine simply does not know you. This fragmentation is normal and is the main reason we check all four separately rather than treating AI search as one channel.
How long until changes show up in these engines?
It varies by engine and we will not pretend to a fixed timeline. Engines that fetch pages live can reflect a new or updated page relatively quickly once they crawl it. Engines that rely more on training data may not reflect a change until a later training cycle or until they retrieve a live page about you. Building citable third-party mentions tends to be the slower part.
Does traditional SEO still matter if I am focused on AI search?
Yes. Gemini and Google AI Overviews sit on top of Google's existing index, so the search fundamentals you already know feed directly into those answers. Strong, well-structured pages also give the live-retrieval engines something clean to fetch and quote. AI search is a layer on top of search, not a replacement for it.
Can I track whether I am actually showing up across all four engines?
You can check manually by asking each engine the questions your customers would ask and noting whether you appear, how you are described, and whether you are cited. That is slow to repeat across four engines every week. AfterLaunch runs that same check across ChatGPT, Claude, Gemini and Perplexity for you, and shows where the answers agree, where they fragment, and where you are missing.